Introduction
Large Language Models (LLMs) Statistics: are sophisticated AI systems built on deep learning, particularly transformer-based architectures, designed to analyze and generate human-like text by identifying statistical patterns within vast datasets. Their core functionality is grounded in probability distributions, enabling precise language prediction and contextual comprehension.
Performance and efficiency are largely determined by metrics such as perplexity, cross-entropy loss, dataset scale, and the number of parameters. With some models incorporating hundreds of billions of parameters, LLMs require immense computational resources and advanced optimization strategies, while statistical benchmarks remain central for evaluating accuracy and coherence.
Beyond the technical scope, LLM statistics also capture adoption trends, enterprise integration, and productivity impacts, with growing attention directed toward transparency, fairness, and bias assessment to ensure responsible AI development.
Editor’s Choice
- To be classified as a large model, LLMs typically require a minimum of 1 billion parameters, with training often relying on massive datasets that span into petabyte scale.
- As of 2023, the leading five developers of LLM technology accounted for nearly 88.22% of global market revenue, underscoring industry concentration.
- Projections suggest that by 2025, around 750 million applications will integrate LLM capabilities across sectors.
- By the same year, LLM-powered solutions are expected to automate close to half of all digital work, reshaping workforce productivity.
- Out of the more than 300 million companies worldwide, recent Iopex figures show that nearly 67% are already adopting generative AI tools dependent on LLMs, particularly for content generation.
- A survey by Datanami in August 2023 revealed that 58% of enterprises are experimenting with LLMs. Still, only 23% have either begun commercial rollouts or have plans to do so, indicating a cautious approach to large-scale deployment.
LLM Development and Training Statistics
- GPT-4 was trained with an estimated 1.76 trillion parameters, making it one of the largest models to date.
- Google’s Gemini 1.5 employs a mixture-of-experts model with around 1.56 trillion parameters.
- Training GPT-4 required an investment of nearly $100 million in compute resources.
- Meta’s LLaMA 2 models are available in configurations of 7B, 13B, and 70B parameters.
- GPT-3 training drew upon 45 TB of text data from diverse sources, including Common Crawl, Books, and Wikipedia.
- GPT-4 training spanned over 90 days, utilizing distributed GPUs across several data centers.
- Anthropic’s Claude 2 applied constitutional AI with supervised learning on curated datasets.
- Training GPT-3 demanded around 355 GPU years of processing power.
- NVIDIA’s H100 GPUs dominate LLM training, offering up to 30x faster speeds compared to A100S.
- GPT-3 training involved 10,000 NVIDIA V100 GPUs, hosted on cloud infrastructure.
- From 2020 to 2024, the cost to train frontier LLMs has dropped by nearly 60%, driven by hardware efficiency gains.
- Training a model like GPT-4 may consume up to 25 MWh of energy, raising sustainability concerns.
- By mid-2024, over 200 open-source LLMs had been publicly released worldwide.
- State-of-the-art models now train on datasets exceeding 1 trillion tokens on average.
- Fine-tuning with domain-specific data can enhance task performance by up to 35%.
(Source: SemiAnalysis, Google DeepMind, The Information, Meta AI, OpenAI, Microsoft Azure AI, NVIDIA, EpochAI, Hugging Face, AI Index Report, Cohere, Anthropic)
Accuracy and Performance Benchmarks of Large Language Models
- GPT-4 ranked in the 90th percentile on the Uniform Bar Exam, highlighting advanced reasoning capabilities.
- Gemini 1.5 surpassed human-level results on 30 of 35 NLP benchmarks, setting new performance standards.
- Claude 2 achieved nearly 90% accuracy in solving grade-school math word problems.
- On the MMLU benchmark, GPT-3.5 scored 82%, while GPT-4 reached 86.4%, reflecting measurable gains.
- GPT-4 Turbo reduced hallucination rates by 35% compared to GPT-3.5, improving reliability.
- LLaMA 2-70B delivered near state-of-the-art results in question answering and summarization tasks.
- Models enhanced with retrieval-augmented generation (RAG) improved factual accuracy by 20–30%.
- Across domains, LLMs show factual hallucination rates ranging between 15% and 27%.
- Multilingual-trained models maintain accuracy within 5% of English benchmarks across the top 10 languages.
- Instruction-tuning boosted task-following performance by up to 40%.
- Chain-of-thought prompting improved reasoning accuracy by as much as 20%.
- On long-context tasks, model accuracy can decline by up to 35% without memory optimization.
- Performance degrades by about 0.5% per million tokens in very long prompts if left unoptimized.
- Math performance varies by ±10% depending on prompt formatting.
- Retrieval-augmented LLMs achieved 92% accuracy in closed-domain QA, compared to 71% for standard models.
(Source: OpenAI, Google DeepMind, Anthropic, Papers with Code, Meta AI, Cohere, Stanford HELM, Hugging Face, DeepMind.)
Large Language Model (LLM) Market Size
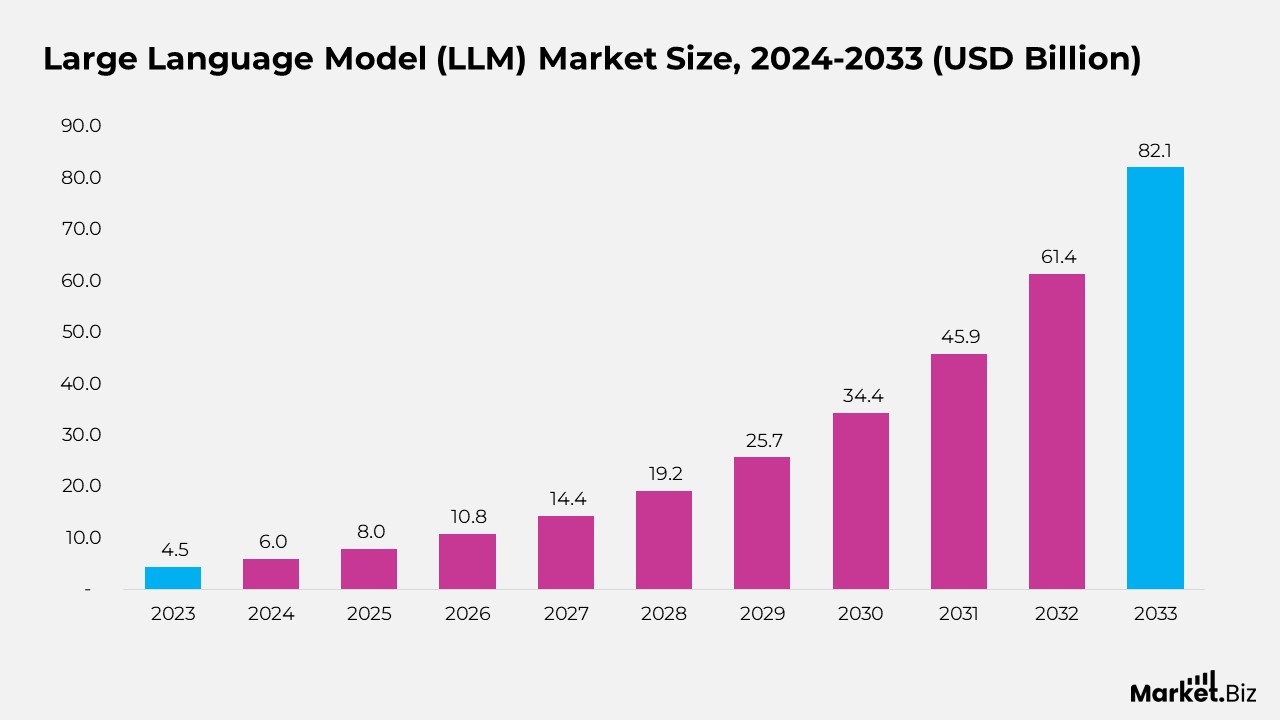
- According to Market.us, the Large Language Model (LLM) market is expected to rise from $8.0 billion in 2025 to $82.1 billion by 2033, representing a compound annual growth rate (CAGR) of 33.7% from 2024 to 2033.
- Market growth is fueled by rising demand for advanced data management and customer interaction solutions, supported by strong R&D investments.
- In 2023, the On-premise segment led the LLM market with a 57.7% share, reflecting its strong performance in a shifting tech landscape.
- In 2024, Chatbots and Virtual Assistants dominated with a 27.1% share, underscoring their importance across industries.
- In 2024, the Retail and E-commerce segment held a 27.5% share, showcasing its pivotal role in enhancing consumer engagement and efficiency.
- North America led the market with a 32.7% share valued at USD 1.47 billion, driven by heavy AI investments and robust infrastructure.
- Globally, 67% of organizations use generative AI tools powered by LLMs, reshaping sectors such as finance and customer services.
- Around 60% of Bank of America clients rely on LLM-based tools for investment and retirement planning.
- Smaller models such as Microsoft’s PHI-2 (2.7 billion parameters) outperform larger ones like Llama-2 in coding tasks, proving efficiency gains from optimization.
- Nearly 50% of organizations report being able to deploy generative AI tools within just 1–4 months.
- Privacy and ethics remain barriers, with only 23% of companies moving toward commercial LLM deployment.
(Source: Market.us)
Digital Language Learning Market Size
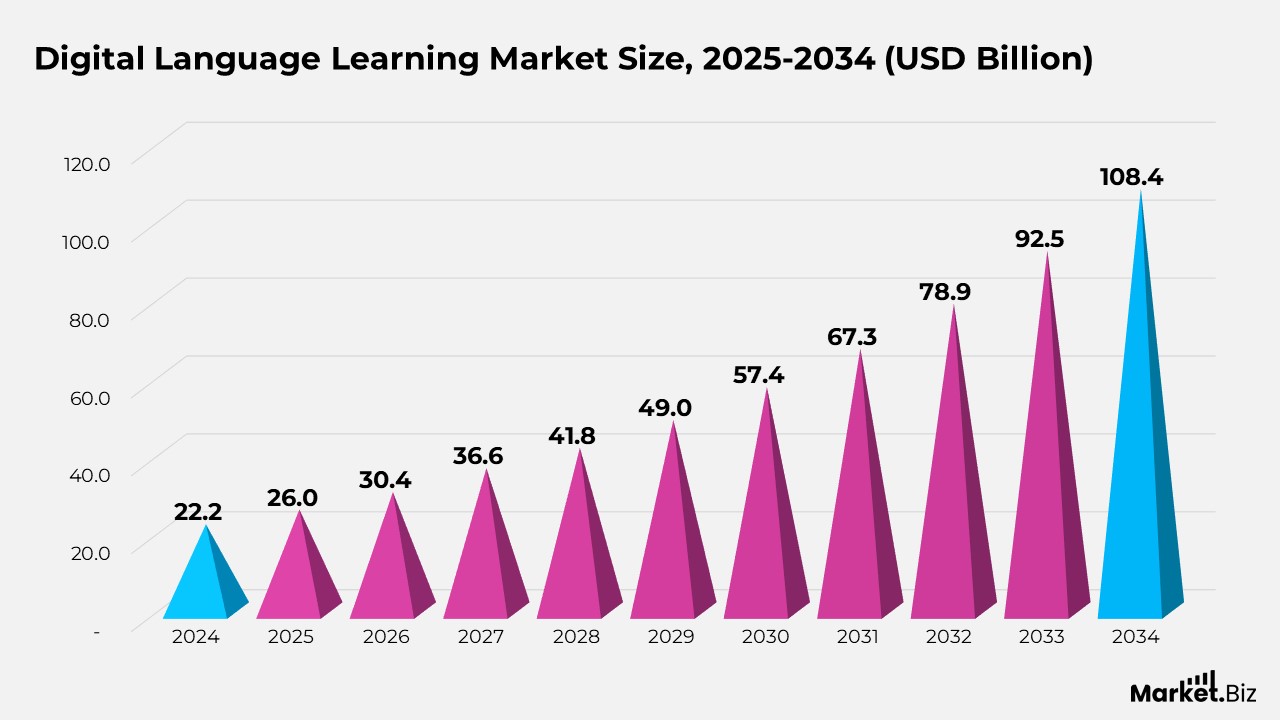
- According to Market.us, the digital language learning market is expected to rise from $25.97 billion in 2025 to $108.5 billion by 2034, representing a compound annual growth rate (CAGR) of 17.2% from 2025 to 2034.
- Market growth is driven by global interconnectivity, technological innovation, and the shift from traditional classrooms to digital platforms.
- By learning mode, Self-Learning Apps led with a 65.1% share, reflecting demand for flexible and on-demand learning options.
- By end user, the Individual segment captured a 43.6% share, fueled by personal and career-focused language learning goals.
- In 2024, the Individual Source segment dominated with a 43.6% share, supported by smartphones, mobile apps, and fast internet adoption.
- The U.S. digital language learning market is valued at USD 7.41 billion with a projected CAGR of 15.4%, driven by AI-powered personalized platforms and globalization.
- In 2024, North America held a 37.1% share, generating USD 8.22 billion, supported by cross-border communication needs and multilingual workforce demand.
- Surveys indicate 65% of learners study languages for personal interest, while 20% focus on career advancement.
- In October 2024, the Quebec government invested USD 54 million to launch a digital French language learning platform.
(Source: Market.us)
Usage and Adoption Trends of Large Language Models
- By 2024, over 100,000 companies worldwide had deployed applications powered by LLMs.
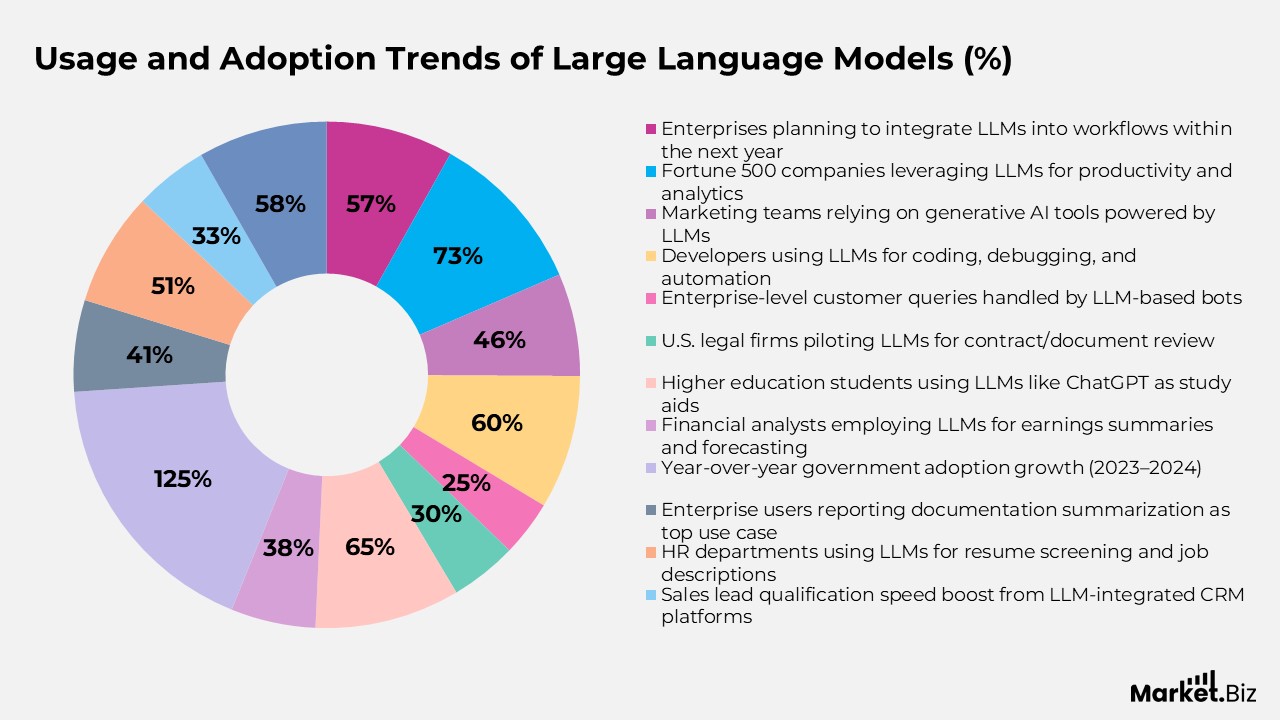
- Around 57% of enterprises are planning to integrate LLMs into workflows within the next year.
- ChatGPT surpassed 100 million weekly active users in early 2024, reflecting mainstream adoption.
- Nearly 73% of Fortune 500 companies leverage LLMs for productivity and data analytics tasks.
- About 46% of marketing teams now rely on generative AI tools driven by LLMs.
- Around 60% of developers use LLMs to support coding, debugging, and task automation.
- Enterprise-level customer service bots powered by LLMs now handle 25% of all queries.
- In the U.S., 30% of legal firms have piloted LLMs for contract review and document summarization.
- Roughly 65% of higher education students use tools like ChatGPT as study aids.
- About 38% of financial analysts employ LLMs for earnings report summaries and forecasting.
- Government adoption of LLMs grew by 125% year-over-year between 2023 and 2024.
- The leading enterprise use case is documentation summarization, reported by 41% of users.
- More than 51% of HR departments deploy LLMs for resume screening and job description drafting.
- CRM platforms integrated with LLMs improved sales lead qualification speeds by an average of 33%.
- Around 58% of global newsrooms use generative AI to draft or edit journalistic content.
(Source: McKinsey, IBM, OpenAI, PwC, Salesforce, Stack Overflow Developer Survey, Gartner, ABA TechReport, EDUCAUSE, Accenture, GovTech, SHRM, Reuters Institute)
Regulation and Ethical Landscape of Large Language Models
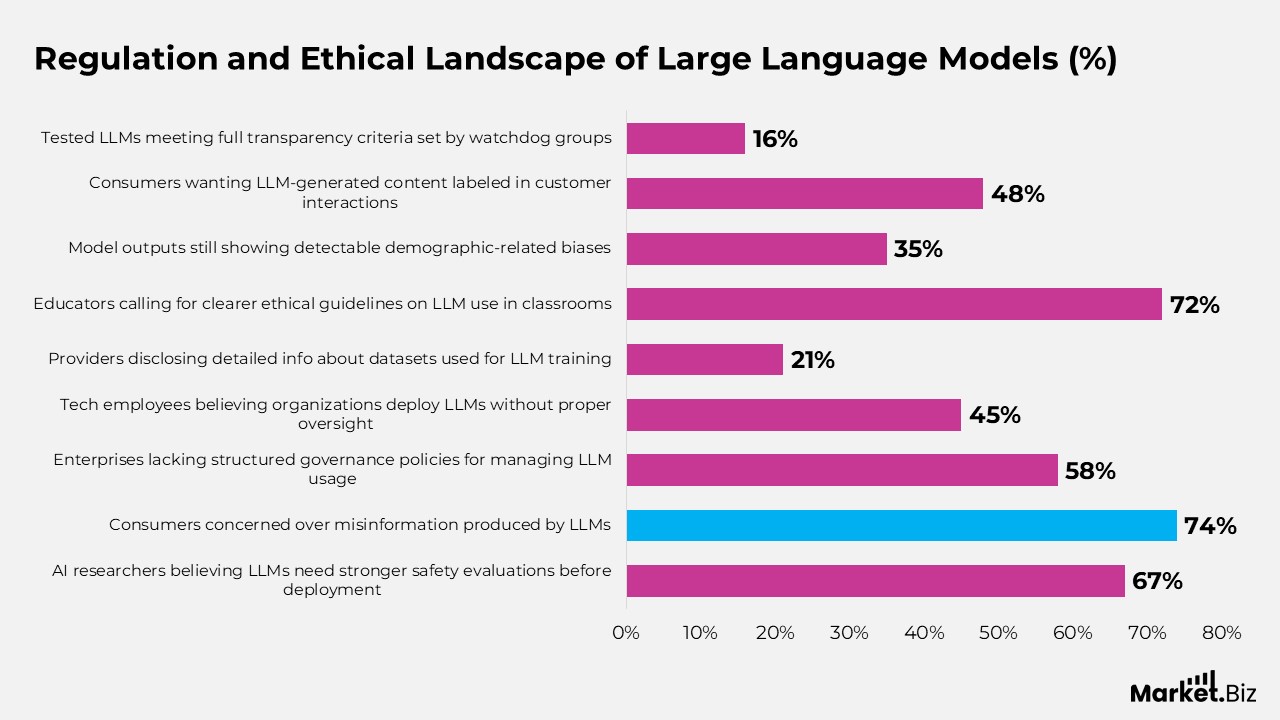
- Between 2023 and 2025, 42 countries introduced or proposed AI regulations addressing LLMs.
- Around 67% of AI researchers believe current LLMs need stronger safety evaluations before deployment.
- The EU AI Act designates general-purpose LLMs as high-risk systems under its draft framework.
- Nearly 74% of consumers express concern over misinformation produced by LLMs.
- The 2023 U.S. Executive Order on AI requires safety testing of foundation models before release.
- About 58% of enterprises lack structured governance policies for managing LLM usage.
- Roughly 45% of tech employees think their organizations deploy LLMs without proper ethical oversight.
- Only 21% of providers disclose detailed information about the datasets used for LLM training.
- The UK’s AI Safety Summit 2023 pledged to evaluate LLMs against catastrophic risk thresholds.
- During the 2024 U.S. elections, LLM-powered campaigns generated 33 ethical complaints.
- Nearly 72% of educators are calling for clearer ethical guidelines on LLM use in classrooms.
- Around 35% of model outputs still show detectable demographic-related biases.
- Compliance costs for enterprise-scale LLM deployment can reach $500,000 per year.
- About 48% of consumers want LLM-generated content clearly labeled in customer interactions.
- Only 16% of tested LLMs met full transparency criteria set by major watchdog groups.
(Source: OECD AI Policy Observatory, AI Impacts Survey 2024, European Commission, Pew Research, White House, Gartner, Blind Survey, AlgorithmWatch, UK Gov, Center for AI and Digital Policy, EDUCAUSE, Stanford CRFM, Deloitte, Ipsos, AI Ethics Lab.)
Deployment and Infrastructure Trends in Large Language Models
- Nearly 94% of LLMs are deployed on cloud platforms, with AWS, Azure, and Google Cloud leading adoption.
- The Azure OpenAI Service has surpassed 53,000 global customers, reflecting strong enterprise demand.
- Anthropic’s Claude leverages Amazon Bedrock to enable serverless model deployment.
- Around 31% of enterprises run LLMs in hybrid-cloud environments for flexibility and control.
- Top commercial APIs maintain an average inference latency of under 500ms, ensuring real-time responsiveness.
- Approximately 12% of organizations host LLMs on-premises to address privacy and compliance concerns.
- NVIDIA’s DGX H100 systems dominate inference workloads as the preferred hardware choice in 2024.
- Vector databases such as Pinecone and Weaviate are used in over 60% of RAG-based deployments.
- Demand for fine-tuning infrastructure expanded by 84% year-over-year between 2023 and 2024.
- Serverless API deployments surged by 150% year-over-year, highlighting rapid scalability.
- On Hugging Face, about 70% of usage relies on hosted inference endpoints.
- Containerized deployments via Docker and Kubernetes rose by 61% among AI startups.
- LLM-powered chatbots emerged as the most frequent inference use case on Google Vertex AI.
- Roughly 42% of development teams now employ model distillation to enhance inference speed.
- GPU rental prices tripled in 2023, driven by soaring demand for inference capacity.
(Source: OECD AI Policy Observatory, AI Impacts Survey 2024, European Commission, Pew Research, White House, Gartner, Blind Survey, AlgorithmWatch, UK Gov, Center for AI and Digital Policy, EDUCAUSE, Stanford CRFM, Deloitte, Ipsos, AI Ethics Lab.)
Workforce and Education Transformation Driven by Large Language Models
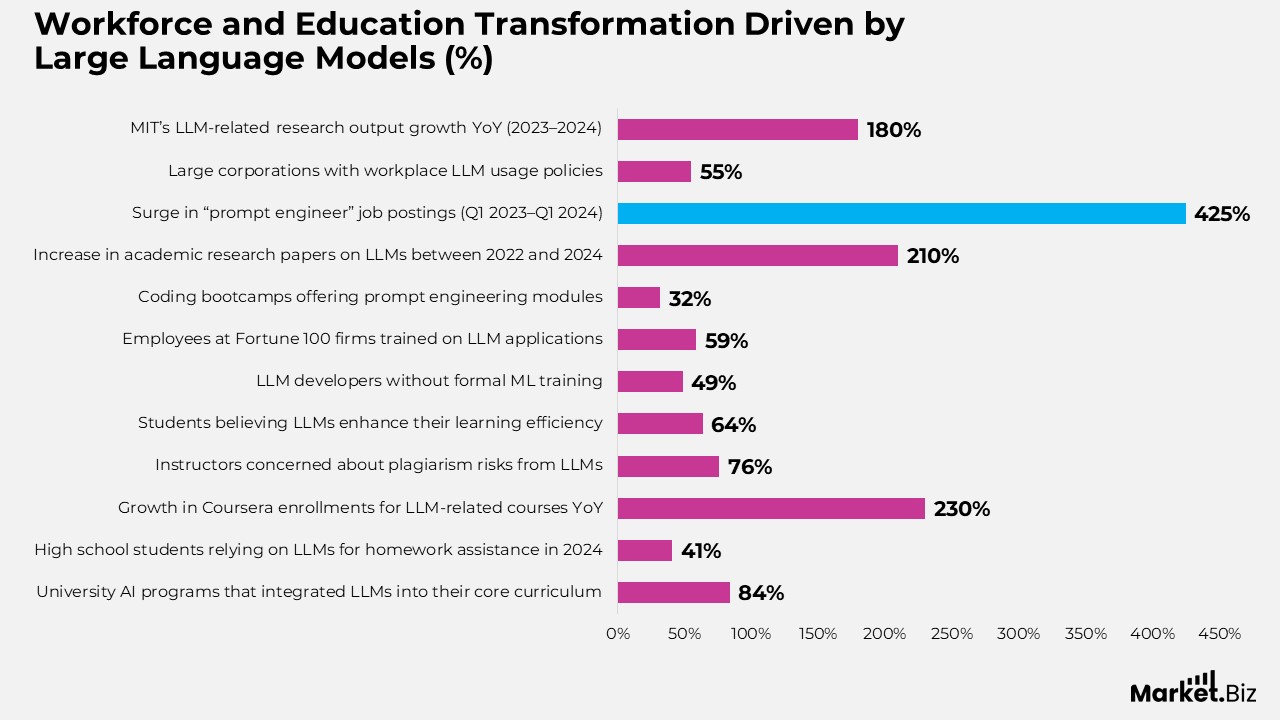
- Around 84% of university AI programs have integrated LLMs into their core curriculum.
- GitHub Copilot, powered by LLM technology, is now used by over 1.5 million developers weekly.
- In 2024, nearly 41% of high school students relied on LLMs for homework assistance.
- Enrollments in LLM-related courses on Coursera grew by 230% year-over-year.
- About 76% of instructors voice concerns over plagiarism risks tied to LLM use.
- AI literacy programs with an LLM focus were launched across 22 countries by mid-2024.
- Nearly 64% of students believe LLMs enhance their learning efficiency.
- Almost 49% of LLM developers report having no formal training in machine learning.
- At Fortune 100 firms, 59% of employees have received training on LLM applications.
- Roughly 32% of coding bootcamps now offer specialized modules on prompt engineering.
- Academic research papers on LLMs increased by 210% between 2022 and 2024.
- Job postings for “prompt engineers” surged by 425% from Q1 2023 to Q1 2024.
- LLM usage policies are in place across 55% of large corporations.
- Google for Education piloted LLM-powered tutoring tools in more than 1,500 schools.
- MIT’s LLM-related research output expanded by 180% year-over-year from 2023 to 2024.
(Source: EDUCAUSE, GitHub, Common Sense Media, Coursera, Inside Higher Ed, UNESCO, Stack Overflow Survey, McKinsey, Course Report, arXiv, Indeed, Gartner, Google, MIT CSAIL.)
Security Challenges, Risks, and Safety Measures in Large Language Models
- About 39% of organizations reported data leakage incidents associated with LLM usage.
- Jailbreak-style prompts succeeded in bypassing safeguards in 27% of models tested.
- Nearly 62% of security experts are concerned about the misuse of open LLM APIs.
- Prompt injection flaws were found in 48% of LLM-based tools currently deployed.
- Around 29% of employees unintentionally exposed sensitive company data through LLMs.
- In AI red-teaming, 89% of teams now include prompt attack testing for LLMs.
- Adversarial inputs reduce LLM accuracy by 20–45%, depending on the attack method.
- Roughly 56% of enterprises lack cybersecurity policies covering LLM usage.
- More than 4,500 security incidents were traced back to LLM-generated code in 2024.
- Personally identifiable information reappeared in 11% of model outputs during red team evaluations.
- Tests showed 43% of models could still be manipulated into generating harmful or toxic content.
- Guardrails and filtering systems cut unsafe outputs by 65% in leading commercial models.
- Retrieval-augmented LLMs proved 30% more resilient against hallucination-driven social engineering threats.
- Safety documentation for foundation models is now a regulatory requirement in 14 countries.
- Automated moderation layers are integrated into 78% of deployed LLM chat apps.
(Source: Cybersecurity Ventures, Anthropic, Palo Alto Networks, OWASP, Stanford HAI, OpenAI, MITRE ATLAS, Gartner, GitHub Security Lab, Stanford CRFM, AI Vulnerability Database, Meta AI, OECD, Salesforce AI)
LLM Fairness and Bias Statistics
- GPT-4 was trained on an estimated 1.76 trillion parameters, while Gemini 1.5 uses a 1.56 trillion parameter mixture-of-experts model.
- Training GPT-4 required $100 million in compute resources, over 90 days, and thousands of distributed GPUs.
- LLaMA 2 models scale across 7B, 13B, and 70B parameters, while GPT-3 training consumed 45 TB of text data.
- By mid-2024, more than 200 open-source LLMs were publicly available, with datasets averaging 1 trillion tokens.
- Fine-tuning with domain-specific data boosts task performance by up to 35%.
- Over 100,000 companies now use LLM-powered applications, and 57% of enterprises plan integration within a year.
- ChatGPT surpassed 100 million weekly users, with 73% of Fortune 500 companies relying on LLMs for productivity.
- LLM-powered bots handle 25% of enterprise customer queries, while 65% of students in higher Education use them for study support.
- Governments expanded usage by 125% year-over-year, and 51% of HR teams deploy LLMs for recruiting tasks.
- GPT-4 ranked in the 90th percentile on the bar exam, scored 86.4% on MMLU, and cut hallucinations by 35% versus GPT-3.5.
- Retrieval-augmented models achieved 92% accuracy in closed-domain Q&A compared to 71% for standard LLMs.
- The global LLM market is projected to hit $91.3 billion by 2030, with enterprises spending $18 billion in 2024 alone.
- Microsoft invested $13 billion in OpenAI, while NVIDIA generated $40 billion in AI chip revenue in 2024.
- Regulatory efforts accelerated, with 42 countries drafting AI laws and the EU classifying LLMs as high-risk systems.
- Nearly 74% of consumers worry about misinformation, and compliance costs can reach $500,000 annually for enterprises.
- Open-source adoption grew 400% between 2022 and 2024, with Vicuna-13B achieving 90% of ChatGPT’s performance at 10% of the cost.
- By 2024, 38% of released models were multimodal, including GPT-4V and Gemini Pro, capable of reasoning across text, images, and audio.
Moreover
- Cloud dominates deployment, with 94% of LLMs hosted on AWS, Azure, or Google Cloud, while 12% remain on-premises.
- Fine-tuning infrastructure demand surged 84% year-over-year, and GPU rental prices spiked 3x in 2023.
- In Education, 84% of universities now teach LLMs in core AI programs, and “prompt engineer” job postings rose 425% in a year.
- Risk remains significant, as 39% of companies faced data leaks, 43% of models generated harmful content under testing, and adversarial attacks cut accuracy by 20–45%.
- Healthcare adoption is accelerating, with GPT-4 reaching 85% accuracy on medical exams and LLMs cutting documentation time by 20%.
- Financial services rely on LLMs for earnings summaries (cut by 58%), CFA exam simulations (87% accuracy), and fraud detection (improved by 21%).
- Bias persists, as GPT-3.5 showed gender bias in 34% of hiring tasks, while GPT-4 reduced racial bias by 67% compared to its predecessor.
- Models with reinforcement learning from human feedback (RLHF) display 50–65% less bias, highlighting progress in fairness optimization.
(Source: SemiAnalysis, The Information, Microsoft, NVIDIA, EpochAI, Hugging Face, AI Index Report, Cohere, McKinsey, IBM, PwC, Salesforce, Stack Overflow, Gartner, ABA TechReport, EDUCAUSE, Accenture, GovTech, SHRM, Reuters Institute, Anthropic, Stanford HELM, DeepMind, IDC, The Verge, Deloitte, OECD, European Commission, Pew Research, AlgorithmWatch, UK Gov, Center for AI and Digital Policy, Stanford CRFM, Ipsos, AI Ethics Lab, Technology Innovation Institute, LAION, LMSYS, Weights & Biases, Together AI, MIT CSAIL, Health Affairs, Mayo Clinic, PLOS Digital Health, Kaiser Permanente, Rock Health, Nature, HIMSS, Optum, Goldman Sachs, CFA Institute, Mastercard, BlackRock, USPTO, Forrester, AlternativeData.org, NeurIPS Survey, Allen Institute, Data & Society, AI Ethics Journal, Cohere.ai.)
Conclusion
Large Language Models (LLMs) mark a significant breakthrough in artificial intelligence, harnessing deep learning and extensive datasets to achieve exceptional proficiency in language comprehension and generation.
Their performance is guided by statistical metrics, computational power, and scalability, which continue to advance as models grow larger and more complex. By driving innovation across industries, LLMs are reshaping productivity, decision-making, and automation, yet their widespread adoption also underscores the need for transparency, fairness, and ethical responsibility.
However, aligning technological progress with responsible governance will be essential in determining the future impact of LLMs and solidifying their position as a foundation of modern AI.
FAQ’s
What is meant by LLM statistics?
LLM statistics refer to the quantitative and performance-related measures of large language models, including model parameters, dataset scale, training efficiency, evaluation benchmarks, and adoption across industries.
The primary metrics include perplexity, cross-entropy loss, benchmark accuracy, and token prediction probabilities. These indicators help evaluate a model’s coherence, contextual understanding, and overall effectiveness.
Cutting-edge LLMs are designed with hundreds of billions of parameters. Some of the most advanced models now exceed 500 billion parameters, highlighting their complexity and resource requirements.
The breadth and diversity of training datasets are critical, as they determine a model’s ability to generalize, capture linguistic subtleties, and minimize bias. Current training often leverages trillions of tokens spanning multiple languages and domains.
Training LLMs requires immense resources, often involving thousands of GPUs and consuming vast amounts of energy. As a result, efficiency and sustainability have become key statistical considerations in their development.
They are evaluated on standardized tasks such as MMLU (Massive Multitask Language Understanding), GLUE, SuperGLUE, and reasoning or coding tests, which provide measurable performance comparisons.